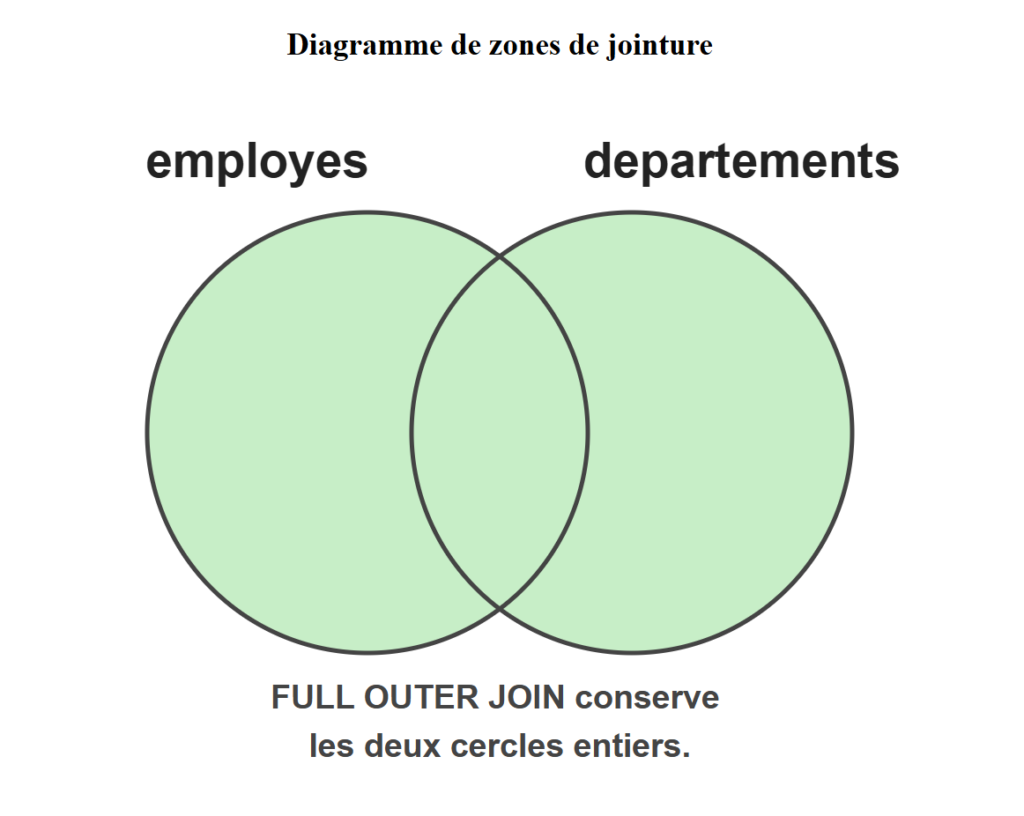
Le FULL JOIN, aussi écrit FULL OUTER JOIN, est une instruction SQL qui conserve l’intégralité des enregistrements des deux tables engagées dans la requête. Lorsqu’une ligne de la table gauche ne trouve aucun équivalent dans la table droite, toutes les colonnes manquantes reçoivent automatiquement la valeur NULL. Ce mécanisme s’applique symétriquement aux lignes de la table droite qui n’ont aucun équivalent à gauche. Aucun enregistrement n’est écarté du résultat, qu’il soit associé ou non à une ligne de l’autre table. C’est ce caractère exhaustif et bidirectionnel qui distingue la jointure complète des autres opérations de liaison SQL.
La jointure complète ne doit pas être confondue avec une jointure croisée, qui génère toutes les combinaisons possibles sans aucune condition d’appariement.
Table des matières
Syntaxe générique de FULL JOIN
La syntaxe du FULL JOIN suit la même structure que les autres liaisons SQL, avec le mot-clé placé entre les deux tables concernées. Le mot-clé OUTER est optionnel dans la syntaxe : il fait référence à la famille des jointures externes, dont le FULL JOIN fait partie. Ainsi, les deux formulations sont fonctionnellement identiques et produisent exactement le même résultat. Une clause ON est obligatoire pour préciser la condition d’appariement entre une colonne de la table gauche et une colonne de la table droite. Sans cette condition, le moteur SQL est incapable de déterminer quels enregistrements doivent être mis en correspondance. PostgreSQL prend en charge cette syntaxe nativement, contrairement à MySQL qui ne supporte pas FULL OUTER JOIN directement.
La syntaxe standard pour écrire une jointure complète entre deux tables s’écrit ainsi :
SELECT table1.colonne1, table2.colonne2
FROM table1
FULL JOIN table2 ON table1.id = table2.id;Cette instruction retourne l’ensemble des lignes des deux tables, avec NULL partout où aucune mise en correspondance n’a abouti. Contrôlez que les colonnes affichant NULL correspondent bien aux enregistrements orphelins dans l’une ou l’autre table.
La forme avec le mot-clé OUTER explicite donne un résultat strictement identique :
SELECT table1.colonne1, table2.colonne2
FROM table1
FULL OUTER JOIN table2 ON table1.id = table2.id;Les deux écritures sont interchangeables dans PostgreSQL et SQL Server, le choix relève uniquement de la convention adoptée dans votre projet. Privilégiez la formulation la plus cohérente avec le reste du code existant dans votre base de données.
Comment fonctionne une jointure complète en SQL ?
La jointure complète associe le comportement d’une liaison gauche et d’une liaison droite en une seule opération appliquée simultanément aux deux tables. Le moteur SQL commence par repérer toutes les lignes de la table gauche qui trouvent un équivalent dans la table droite selon la condition définie dans ON. Les paires identifiées sont intégrées au résultat avec leurs valeurs respectives issues des deux tables. Les lignes de la table gauche sans équivalent sont ensuite ajoutées, avec des valeurs NULL pour toutes les colonnes provenant de la table droite. Les lignes orphelines de la table droite sont traitées de façon symétrique, avec des valeurs NULL pour toutes les colonnes issues de la table gauche.
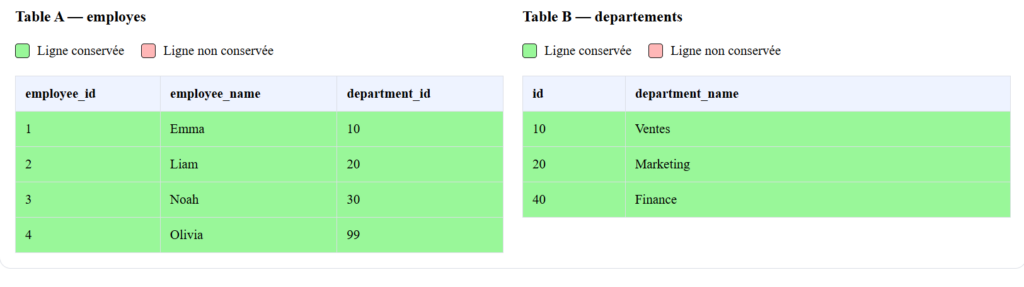
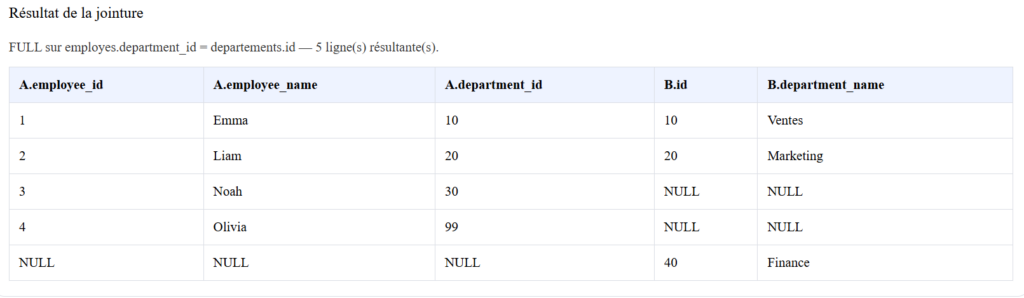
L’exemple suivant illustre ce mécanisme avec une table employes et une table departements dont certains enregistrements ne sont liés à aucun équivalent :
SELECT employes.nom, departements.nom_dept
FROM employes
FULL JOIN departements ON employes.id_dept = departements.id_dept;Le résultat intègre les employés sans département assigné et les départements sans aucun membre rattaché. Les colonnes issues de la table sans équivalent affichent NULL pour chaque ligne orpheline présente dans le résultat.
Intéressant à lire également
SQL JOINS VISUALIZER: Comprendre les jointures avec notre outil visuel interactif
L’interface se divise en plusieurs sections qui collaborent pour illustrer le comportement d’une opération de jointure SQL. Vous sélectionnez un type de jointure et un jeu de données, puis l’outil calcule automatiquement le résultat de la requête. Un diagramme de zones de jointure coloré en vert indique visuellement quelle partition des données est conservée selon la jointure active.
Pourquoi utiliser une jointure complète ?
La jointure complète est pertinente lorsqu’il est nécessaire d’obtenir une vue exhaustive de deux tables sans sacrifier aucun enregistrement, même ceux sans équivalent. Ce besoin se manifeste lors d’un audit de données, pour repérer les incohérences entre deux tables censées être synchronisées. Elle permet par exemple d’identifier en une seule requête les clients sans commande enregistrée et les commandes sans client associé. Ce type d’opération est également courant lors d’une migration de base de données, pour confronter les données sources aux données cibles ligne par ligne. La jointure complète garantit qu’aucune anomalie ne passe inaperçue lors d’une vérification d’intégrité entre deux ensembles de données distincts.
L’exemple suivant confronte deux tables d’inventaire pour détecter les écarts entre un état initial et un état final après mise à jour :
SELECT a.id_produit, a.stock AS stock_avant, b.stock AS stock_apres
FROM inventaire_avant a
FULL JOIN inventaire_apres b ON a.id_produit = b.id_produit;Les produits présents uniquement dans inventaire_avant affichent NULL dans la colonne stock_apres, et inversement pour les nouveaux articles. Vérifiez que chaque valeur NULL correspond bien à un article ajouté ou retiré entre les deux états de l’inventaire.
Comment faire une jointure totale en SQL ?
Dans PostgreSQL et SQL Server, l’instruction FULL JOIN s’exécute directement avec une clause ON sans configuration particulière. Dans MySQL, cette syntaxe n’est pas prise en charge nativement : le moteur retourne une erreur lors de l’exécution d’un FULL OUTER JOIN. La méthode de contournement consiste à combiner un LEFT JOIN et un RIGHT JOIN via l’opérateur UNION, qui fusionne les deux jeux de résultats en supprimant les doublons. Il est impératif d’utiliser UNION plutôt que UNION ALL pour éviter de dupliquer les lignes appariées présentes dans les deux sous-requêtes. Cette approche produit un résultat fonctionnellement équivalent à une véritable jointure complète sur les mêmes données.
Intéressant à lire également
Le point le plus difficile à assimiler dans les sous-requêtes est leur ordre d'exécution : la sous-requête est traitée avant la requête principale, et non pas de haut en bas comme on lirait du code. L'outil rend cet ordre explicite en forçant l'apprenant à passer par l'étape de la sous-requête avant de…
Dans PostgreSQL ou SQL Server, voici comment cibler uniquement les enregistrements orphelins des deux tables avec un filtre sur les valeurs absentes :
SELECT employes.nom, departements.nom_dept
FROM employes
FULL JOIN departements ON employes.id_dept = departements.id_dept
WHERE employes.id_dept IS NULL OR departements.id_dept IS NULL;Cette requête isole uniquement les lignes sans équivalent dans l’une ou l’autre table, ce qui est idéal pour un audit ciblé sur les anomalies. Vérifiez qu’aucune ligne du résultat n’affiche simultanément une valeur non NULL dans les deux colonnes filtrées.
Dans MySQL, voici la méthode de substitution complète avec LEFT JOIN, UNION et RIGHT JOIN :
SELECT employes.nom, departements.nom_dept
FROM employes
LEFT JOIN departements ON employes.id_dept = departements.id_dept
UNION
SELECT employes.nom, departements.nom_dept
FROM employes
RIGHT JOIN departements ON employes.id_dept = departements.id_dept;L’opérateur UNION fusionne les deux résultats en éliminant automatiquement les lignes communes issues des enregistrements appariés dans les deux sous-requêtes. Contrôlez que le volume de lignes retourné correspond bien à l’addition des enregistrements orphelins des deux tables, plus les lignes appariées.
Quand utiliser une jointure complète plutôt qu’une autre jointure ?
La jointure complète se justifie uniquement lorsque les enregistrements orphelins des deux tables ont une valeur métier et ne doivent pas être écartés du résultat. Si seules les lignes sans équivalent d’une unique table sont utiles, une liaison gauche ou droite avec un filtre WHERE ... IS NULL répond au besoin avec un coût en ressources moindre. Lorsque seuls les enregistrements appariés présentent un intérêt, une liaison interne reste l’option la plus efficace sur le plan des performances. La jointure complète est donc réservée aux situations où l’exhaustivité absolue des deux côtés constitue une exigence fonctionnelle explicite et documentée. Sur des tables volumineuses, son coût est significatif : n’y recourir que lorsqu’aucune alternative plus ciblée ne couvre le besoin réel.
Sources: Postgres