Le RIGHT JOIN, aussi écrit RIGHT OUTER JOIN, est une instruction SQL qui garantit la conservation de chaque enregistrement de la table prioritaire, celle placée après le mot-clé. Lorsqu’une ligne de cette table prioritaire ne trouve aucun équivalent dans la table secondaire, les colonnes issues de cette dernière reçoivent automatiquement la valeur NULL. Les paires identifiées par la condition de liaison sont intégrées au résultat avec leurs valeurs respectives des deux côtés. Le mot-clé OUTER est facultatif : les deux formulations sont fonctionnellement identiques selon la norme SQL ISO/IEC. C’est la position des tables dans la requête qui détermine laquelle est prioritaire et laquelle est secondaire.
Table des matières
Syntaxe générique de RIGHT JOIN
La syntaxe du RIGHT JOIN suit la même structure que les autres liaisons SQL, avec une clause ON obligatoire pour définir la condition d’appariement. Sans cette condition, le moteur SQL est incapable d’évaluer quelles lignes doivent être mises en correspondance entre les deux tables engagées. Une syntaxe alternative avec USING est disponible lorsque la colonne de liaison porte exactement le même nom dans les deux tables. MySQL et PostgreSQL supportent tous deux cette opération nativement, sans paramétrage particulier. La clause ON accepte plusieurs conditions combinées avec AND pour affiner les critères d’appariement selon les besoins du modèle de données.
La syntaxe standard pour écrire cette liaison s’écrit ainsi :
SELECT table1.colonne1, table2.colonne2
FROM table1
RIGHT JOIN table2 ON table1.id = table2.id;Toutes les lignes de table2 apparaissent dans le résultat, complétées par les valeurs de table1 lorsqu’une correspondance existe. Les colonnes de table1 affichent NULL pour chaque enregistrement de table2 sans équivalent dans la table secondaire.
Lorsque la colonne de liaison porte le même nom dans les deux tables, la syntaxe avec USING allège l’écriture :
SELECT table1.colonne1, table2.colonne2
FROM table1
RIGHT JOIN table2 USING (id);Cette formulation est strictement équivalente à la précédente sur le plan du résultat produit. Vérifiez que la colonne mentionnée dans USING existe avec le même nom et le même type dans les deux tables avant d’utiliser cette syntaxe.
Comment fonctionne une jointure droite en SQL ?
Le moteur SQL parcourt d’abord l’intégralité des enregistrements de la table prioritaire, celle indiquée après RIGHT JOIN. Pour chaque ligne de cette table, il recherche un équivalent dans la table secondaire selon le critère défini dans ON. Lorsqu’une paire est identifiée, les valeurs des deux tables sont assemblées en une seule ligne dans le résultat retourné. Lorsqu’aucun équivalent n’existe, la ligne de la table prioritaire est conservée avec des valeurs NULL pour toutes les colonnes issues de la table secondaire. Les enregistrements de la table secondaire sans équivalent dans la table prioritaire sont en revanche entièrement exclus du résultat.
L’exemple suivant illustre ce mécanisme avec une table commandes et une table clients, dont certains comptes n’ont jamais généré d’achat :
SELECT commandes.id_commande, clients.nom
FROM commandes
RIGHT JOIN clients ON commandes.id_client = clients.id_client;L’intégralité des comptes clients apparaît dans le résultat, même ceux sans aucune commande enregistrée dans la table transactionnelle. Les colonnes issues de commandes affichent NULL pour les comptes inactifs, ce qui permet d’identifier immédiatement les clients sans historique d’achat.
Intéressant à lire également
SQL JOINS VISUALIZER: Comprendre les jointures avec notre outil visuel interactif
L’interface se divise en plusieurs sections qui collaborent pour illustrer le comportement d’une opération de jointure SQL. Vous sélectionnez un type de jointure et un jeu de données, puis l’outil calcule automatiquement le résultat de la requête. Un diagramme de zones de jointure coloré en vert indique visuellement quelle partition des données est conservée selon la jointure active.
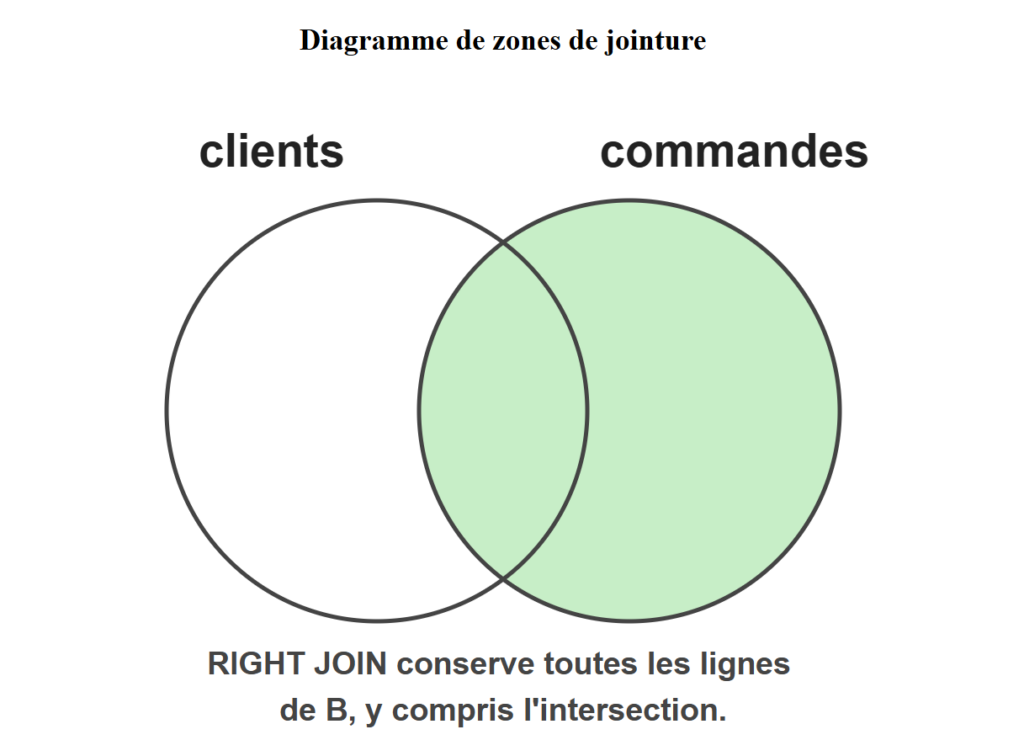
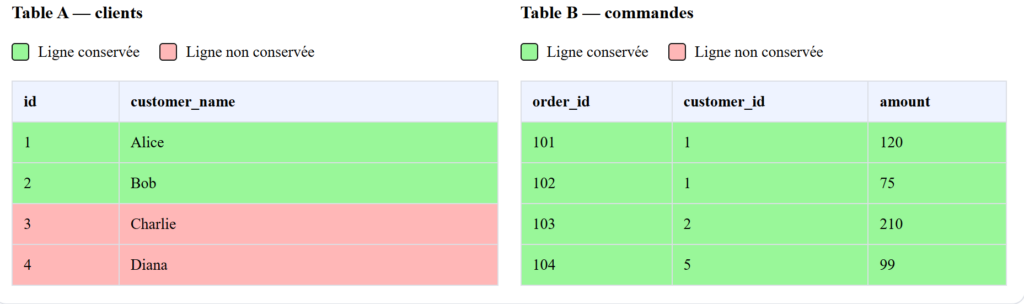
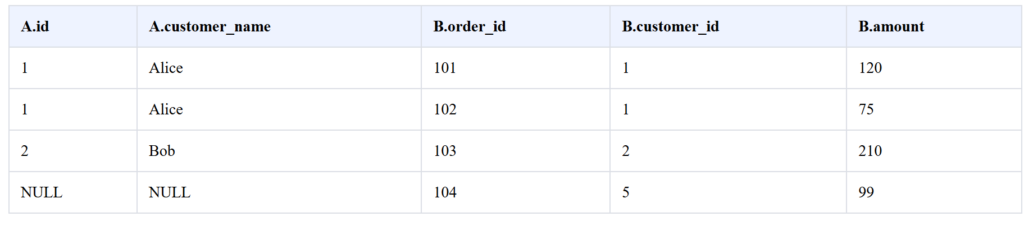
Intéressant à lire également
Notre éditeur SQL en ligne fonctionne entièrement dans le navigateur, sans serveur ni installation requise. Il utilise la bibliothèque sql.js pour exécuter des requêtes SQLite directement en JavaScript. Toutes les données restent sur votre machine et ne sont jamais envoyées à un serveur distant. Écrire et exécuter une requête avec…
La position des tables change-t-elle le résultat d’un RIGHT JOIN ?
La position des tables est déterminante : la table placée après RIGHT JOIN est systématiquement la table dont chaque enregistrement est conservé dans le résultat. Intervertir les deux tables sans modifier le mot-clé produit un résultat différent, car la table prioritaire bascule de côté. En revanche, intervertir l’ordre des tables et remplacer simultanément RIGHT JOIN par LEFT JOIN produit un résultat strictement identique sur les mêmes données. Cette symétrie est confirmée par la documentation officielle MySQL et PostgreSQL, qui précisent que les deux opérations sont des miroirs l’une de l’autre. C’est précisément cette propriété qui permet de réécrire tout RIGHT JOIN sous forme de jointure gauche sans altérer le comportement de la requête.
Les deux requêtes suivantes produisent un résultat identique malgré des structures opposées :
-- Formulation avec jointure droite
SELECT commandes.id_commande, clients.nom
FROM commandes
RIGHT JOIN clients ON commandes.id_client = clients.id_client;
-- Formulation symétrique avec jointure gauche
SELECT commandes.id_commande, clients.nom
FROM clients
LEFT JOIN commandes ON clients.id_client = commandes.id_client;Les deux requêtes retournent le même ensemble de lignes avec les mêmes valeurs NULL aux mêmes positions dans le résultat. Vérifiez que le volume de lignes retourné est identique dans les deux cas pour confirmer l’équivalence sur vos données réelles.
Intéressant à lire également
FOREIGN KEY CONSTRAINT VISUALIZER
L'outil décompose un scénario complet en 6 étapes navigables pas à pas pour matérialiser visuellement la différence entre un INSERT accepté (ligne verte dans la table commandes) et un INSERT rejeté (table commandes inchangée, bannière rouge). Cette distinction visuelle immédiate ancre la compréhension que le rejet est total : aucune donnée partielle n'est jamais écrite en base…
Pourquoi et quand utiliser une jointure droite en SQL ?
Cette opération de liaison est pertinente lorsque la table de référentiel, celle qui ne doit perdre aucun enregistrement, est déjà positionnée à droite dans une requête existante. Ce cas se manifeste fréquemment lorsqu’une table de référence comme produits, clients ou catégories est intégrée en second dans une requête structurée autour d’une table transactionnelle. Réécrire entièrement l’ordre des tables pour déplacer le référentiel à gauche peut alourdir la maintenance d’une requête déjà complexe. Dans un contexte d’audit d’intégrité, cette liaison permet de vérifier que chaque entrée d’un référentiel possède bien des données associées dans une table d’activité. Elle est également utilisée pour générer des rapports d’exhaustivité qui recensent toutes les entités d’un référentiel, avec ou sans activité enregistrée sur la période analysée.
L’exemple suivant liste l’intégralité du catalogue produits avec les ventes associées, y compris les références jamais commercialisées :
SELECT ventes.montant, produits.nom_produit
FROM ventes
RIGHT JOIN produits ON ventes.id_produit = produits.id_produit;Toutes les références du catalogue apparaissent dans le résultat, même celles dont la colonne montant est vide. Ce jeu de données permet d’identifier sans ambiguïté les articles pour lesquels aucune transaction n’a été enregistrée sur la période.
Pourquoi utiliser une jointure droite plutôt qu’une jointure gauche ?
Sur le plan des performances, aucune différence mesurable n’existe entre les deux opérations appliquées aux mêmes tables et aux mêmes données. La documentation officielle MySQL confirme que le moteur d’optimisation traite les deux liaisons de manière symétrique et produit des plans d’exécution équivalents. Le choix entre les deux relève donc uniquement de la lisibilité du code et de la convention adoptée dans le projet. Lorsque la table prioritaire est déjà à droite dans une requête multi-tables complexe, la jointure droite exprime l’intention de façon plus directe sans nécessiter de réorganisation structurelle. Dans les autres cas, la jointure gauche est généralement préférée pour uniformiser le sens de lecture du code SQL au sein d’une équipe.
Peut-on remplacer la jointure droite par une jointure gauche ?
Oui, toute jointure droite peut être transformée en jointure gauche en intervertissant l’ordre des deux tables dans la requête. Cette transformation produit un résultat strictement identique, car la logique d’appariement et les critères de conservation des enregistrements restent inchangés. La quasi-totalité des équipes de développement applique cette convention pour homogénéiser le code et réduire la charge cognitive lors des revues. Un code qui n’utilise qu’une seule orientation de liaison est plus lisible et plus rapide à auditer qu’un code qui alterne les deux sens sans justification structurelle. Cette pratique est largement répandue dans les projets SQL professionnels et constitue une convention de lisibilité reconnue.
Voici la transformation d’une jointure droite en liaison gauche équivalente sur le même besoin métier :
-- Formulation initiale avec jointure droite
SELECT ventes.montant, produits.nom_produit
FROM ventes
RIGHT JOIN produits ON ventes.id_produit = produits.id_produit;
-- Réécriture équivalente avec jointure gauche
SELECT ventes.montant, produits.nom_produit
FROM produits
LEFT JOIN ventes ON produits.id_produit = ventes.id_produit;Les deux requêtes retournent le même résultat avec les mêmes valeurs NULL pour les références sans transaction. Contrôlez que le volume de lignes est identique dans les deux cas pour valider l’équivalence sur vos données réelles.
Comment détecter des enregistrements orphelins avec un RIGHT JOIN ?
Un enregistrement orphelin est une ligne de la table prioritaire qui ne trouve aucun équivalent dans la table secondaire selon le critère de liaison. Pour les isoler, une clause WHERE filtre les lignes dont une colonne issue de la table secondaire affiche NULL. Cette technique est couramment utilisée pour auditer la cohérence entre deux tables liées par une clé étrangère dans un schéma relationnel. Elle permet de repérer des clients sans commande, des produits sans catégorie assignée, ou des employés sans unité organisationnelle rattachée. La colonne utilisée dans le filtre WHERE doit impérativement provenir de la table secondaire pour que l’isolation des lignes orphelines fonctionne correctement.
L’exemple suivant extrait toutes les références du catalogue pour lesquelles aucune transaction de vente n’a jamais été enregistrée :
SELECT produits.id_produit, produits.nom_produit
FROM ventes
RIGHT JOIN produits ON ventes.id_produit = produits.id_produit
WHERE ventes.id_produit IS NULL;Seules les références absentes de la table ventes apparaissent dans ce résultat, ce qui cible précisément les anomalies d’intégrité à corriger. Vérifiez que la colonne filtrée dans WHERE provient bien de la table secondaire ventes et non de la table prioritaire produits pour obtenir le comportement attendu.